
Chest X-rays are the most prescribed medical images. Any improvement in the process of reading and reporting on these images can have a meaningful impact on the radiology workflow. With the recent revolutionary advances in artificial intelligence (AI), especially in deep learning for computer vision and natural language processing, we now have an opportunity to change the way chest X-ray images are used in the clinic. The AI and medical imaging scientists at IBM Almaden Research Center in San Jose, CA, have been at the forefront of activities in this area. We have benefited from datasets of chest X-ray images in the public domain to develop AI models for reading X-rays that match the performance of radiology residents. Now, we are giving back to the community by publishing a new multimodal dataset of radiologist eye-tracking, along with localized disease labels, as described in "Creation and validation of a chest X-ray dataset with eye-tracking and report dictation for AI development" that was just published in Nature Scientific Data.
To understand the significance of this new dataset, let me first preface it with some background information. Multiple research groups, such as the NIH, Stanford University, and MIT/Beth Israel Deaconess Medical center, among others, have open-sourced datasets containing hundreds of thousands of chest X-ray images, with ground-truth annotations related to a limited number of common radiologic findings. This has created growing academic research interest in AI model development for disease detection in chest X-rays. Given the high cost of localized annotation of medical images, the labels in these datasets are in the form of global tags as opposed to local markings of the findings. Researchers have been successful in tagging X-ray images with global labels (say "Consolidation"), but not as successful in mapping it to an area of the lung. The result is that building interpretable AI models for chest X-ray disease detection remains difficult and an open research problem. Furthermore, current AI models can learn from data but are often oblivious to how a radiologist reads X-ray images. While activation map methodologies (such as GradCAM) can highlight areas of the image that contribute to the determination of a label, these are often hard to interpret. For example, they often highlight areas of the image that seem irrelevant to the detected disease. In other words, it is hard to explain why a certain label, even a correct one, is returned by the model. AI interpretability is of paramount importance for building trust in real clinical applications.
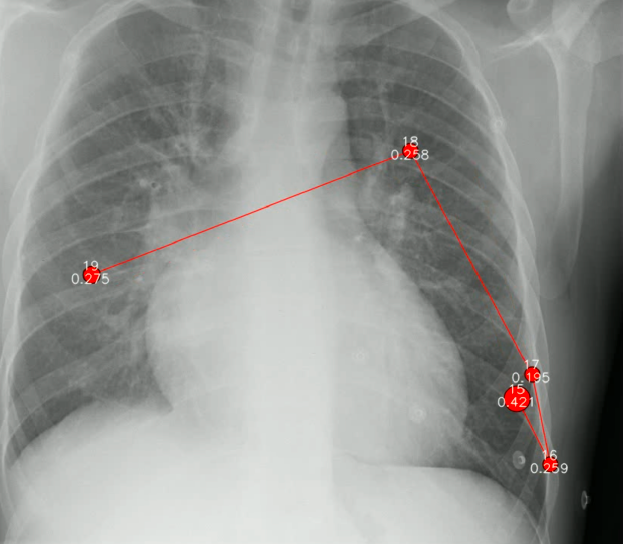
To help the research community overcome these issues, we recently published a multimodal dataset on PhysioNet which is the topic of our Scientific Data article. The dataset provides additional rich information for 1083 chest X-ray images in the MIMIC-CXR Database. Our new data consists of transcribed radiology report text, radiologist's dictation audio, and eye gaze coordinates. All these multimodal data types were collected while a radiologist read the X-ray image, with eye gaze tracked, and the dictation of the report recorded and synced with the eye gaze coordinates.
This unique dataset can help researchers build domain-expert-guided interpretable AI models. As we demonstrated in the article, we were able to produce more accurate activation maps using this data. In addition, eye-track data and the localization of the disease could be used to devise novel loss functions for training neural networks and perhaps, a deeper synergy between radiologists and AI.
We anticipate that the release of this dataset will help the AI healthcare research community to develop more interpretable AI models. Given the multitude of data types and the complexity of the recording task, a dataset of this type cannot be as large as raw image datasets. Nevertheless, the expansion of the dataset with more images and more readers is a worthy cause to pursue based on the feedback from the research community, and we hope that several research teams and developers will follow-up with open-sourcing similar datasets. To help facilitate future work, we open-sourced our entire experimental setup, with detailed information on the eye-gaze device model, data acquisition protocols and post-processing, and initial deep learning based experiments so that interested users can further expand on this dataset and build a larger corpus of multi-modal data.




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in