
Across the Web, large amounts of scientific and health-related information are becoming available at blistering speeds. However, much of this new information is difficult to understand without an advanced degree in the life sciences. How can we make the information in these articles more understandable and accessible for the general public at the same breakneck speeds they are becoming available?
A new gold-standard dataset for biomedical text adaptation
One solution is the use of AI models that automatically simplify or “adapt” the language of biomedical literature to plain language. That being said, these models require high-quality, gold-standard datasets to properly evaluate their performance. In a recently published paper, “A dataset for plain language adaptation of biomedical abstracts,” we (at the National Library of Medicine) introduce a gold-standard dataset that can benchmark these text adaptation models. In addition, we create our own AI models trained and tested on this dataset to set baselines for future research, with publicly-released code available to reproduce our results.
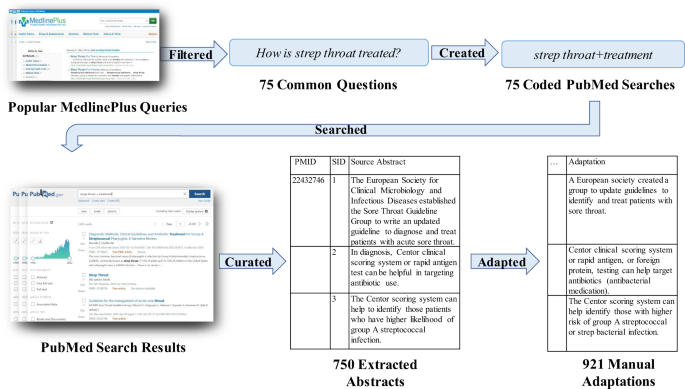
Like existing datasets proposed for this task, our new dataset, named PLABA (Plain Language Adaptation of Biomedical Abstracts), contains pairs of professional-level and plain-language text covering the same material. However, other datasets in the biomedical domain are either paired at the document level or were automatically (and imperfectly) mined at the sentence level with search and alignment algorithms. PLABA uniquely builds on these by adapting PubMed abstracts sentence-by-sentence with human annotators (Figure 1). The abstracts were chosen to address common consumer health questions (e.g., “how is strep throat treated?”) submitted to MedlinePlus, a website developed by the National Library of Medicine to reliably explain health information in plain language. They range from topics like COVID-19 symptoms to genetic conditions like cystic fibrosis. The end result is a dataset with 750 abstracts, addressing 75 questions with 10 abstracts each, and 921 manually-created, gold-standard adaptations, with some abstracts adapted more than once to assess inter-annotator agreement.

What can be done with PLABA?
To aid future research and development of text adaptation models trained and tested on PLABA, we present results of applying 6 AI models to this dataset as baselines. These models are all Large Language Models, which are “pretrained” on large amounts of unlabeled text and can then be “fine-tuned” to perform many natural language processing (NLP) tasks, including translation, text generation, and text simplification. Four of the models we train on a portion of the dataset (labeled the training and validation sets) and test on another portion (labeled the test set). The remaining two models are designed to be “zero-shot,” meaning they can perform tasks never seen in their training without fine-tuning. For these models, we thus skip training and directly evaluate them on the test set. In our results, the fine-tuned models performed noticeably better than the zero-shot models. An overview of the experiments is shown in Figure 2.

How can you use PLABA and contribute?
Download PLABA from our OSF repository and (if desired) our GitHub code with instructions to reproduce our results.
We expect that PLABA and our benchmarked models – both of which are publicly available – will catalyze development of new, leading-edge text adaptation models, and eventually the creation of a public-facing tool that automatically adapts and simplifies online health information into language that anyone can understand.


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in