For a scientist, generating data is a daily exercise. Over the past few years, the amount and the complexity of the data has increased tremendously, and historic data formats now often do not capture the full extent of information retrieved. To improve the findability, accessibility, interoperability and reusability of complex data there is an ongoing adaptation towards using RDF as a single unifying data model and currently many datasets have been made available using this model.
The beauty of using Linked Data is the simplicity and flexibility in capturing the relationship between one piece of data and another piece of data by simply using an RDF link. Through the development of ontologies one can describe the intended relationships and specify its cardinalities giving guidance to the transformation of data into structured datasets with a high degree of interoperability. The freedom of the RDF data model to link anything with everything however also has a downside since unintended links are easily made. Correct implementation of an ontology as was intended by the designer can be a complex task as an ontology can contain hundreds if not thousands of elements describing all sorts of relationships.
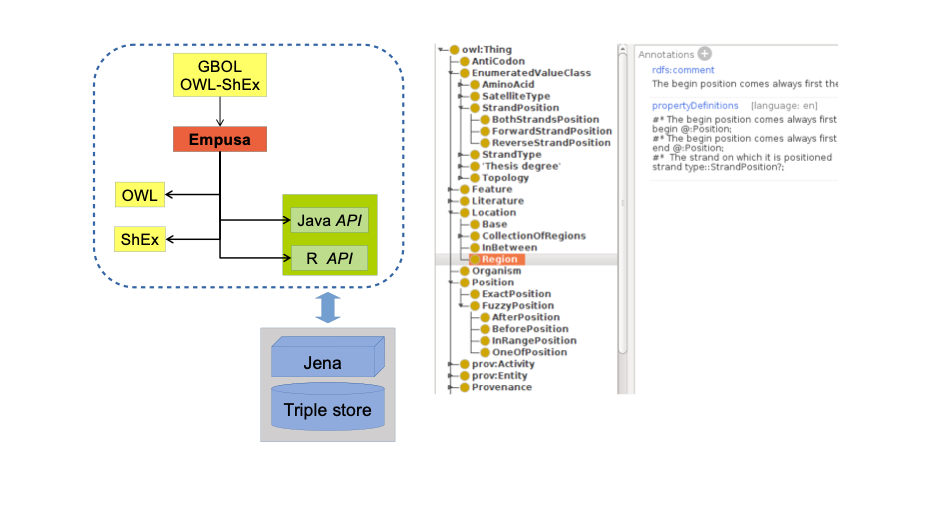
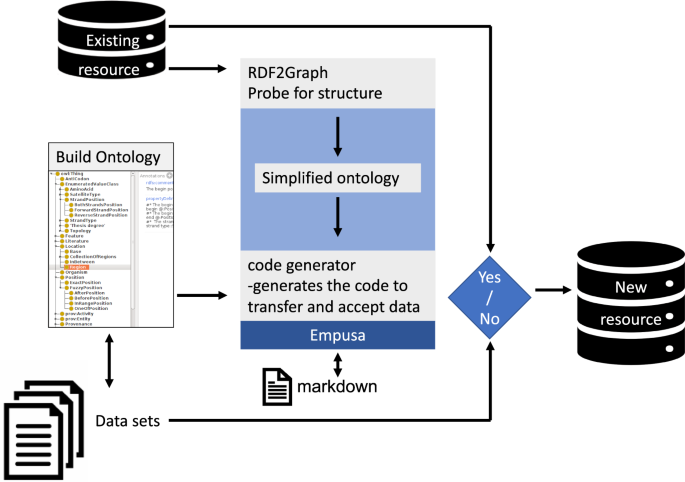
This also happened to us when we were developing the ontologies. During its development we realized that to ease the understanding of the ontology and to ensure correct usage by us or other data scientists a different approach was required. To bridge this gap, we have developed Empusa (empusa.org). Empusa, a code generator for ontologies and its application to GBOL, an extendable ontology for genome annotation.
This application uses a combination of OWL/SheX, enabling rapid ontology development and in addition generates an API ensuring usage of the ontology as was intended by the designer. For example, a book which is a class according to the OWL syntax, can be easily restricted to ensure that a title and abstract are obligatory, but an author can be optional as it is not always known. When creating a book instance using the API a title and abstract are to be provided upon completion of the entry otherwise the API will not allow this book instance to be created. This simple but trivial task ensures that datasets remain consistent as was intended by the designer of the ontology.
In addition, Empusa can also generate markdown files which in turn can be compiled to a website making it easy to have resolvable URL’s from the designed ontology. The first ontology we have developed using Empusa was the Genome Biology Ontology Language (gbol.life). This ontology captures a large variety of genetic information making it possible to have this information from for example viruses, bacteria, plants and humans accessible through a simple but powerful query language. GBOL currently consists of more than 200 class types each with its own restrictions. For example, a protein instance should always have the protein sequence as without it the Empusa API will not allow the generation of such entity.
With Empusa we aim to help the community with the development of higher quality ontologies and through the API correct usage of the ontologies. Through GBOL we propose a new ontology which can be used to capture complex genomic information in a feasible manner.





Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in